분류 모형 성능 지표 - 제1종 오류, 제2종 오류
- 정상과 이상을 예측하는 이진 분류에 대해 confusion matrix를 생성할 수 있음
- 정상을 positive, 불량을 negative라고 정의하고, 맞출 경우를 True, 틀릴 경우를 False라고 한다면 다음과 같은 confusion matrix가 생성됨
- 이때 FP(False Positive)와 FN(False Negative)는 각각 제1종 오류와 제2종 오류에 대응함

분류 모형 성능 지표 - 정확도, 정밀도, 재현율, 특이도
- 정확도(accuracy)는 전체 데이터 중에서 모형으로 예측한 값이 실제 값에 일치하는 비율
- Accuracy = 옳게 분류된 데이터의 수 / 전체 데이터의 수 = (TP+TN) / (TP+FN+FP+TN)
- 정밀도(precision)는 분류 모형이 불량을 진단하기 위해 얼마나 잘 작동했는지를 보여주는 지표
- Precision = 옳게 분류된 불량 데이터의 수 / 불량으로 예측한 데이터 = TN / (FN+TN)
- 재현율(Recall)은 실제 불량 데이터의 수 중에서 실제로 불량이라고 예측한 비율
- Recall = 옳게 분류된 불량 데이터의 수 / 실제 불량 데이터의 수 = TN / (FP +TN)
- 특이도(Specificity)는 분류 모형이 정상을 진단하기 위해 잘 작동하는지를 보여주는 지표
- Specificity = 옳게 분류된 정상 데이터의 수 / 실제 정상 데이터의 수 = TP / (TP + FN)
분류 모형 성능 지표 - G-mean, F1 measure
- Class imbalanced 문제: 불량 데이터를 탐지하는 것이 중요한데 불량 데이터가 매우 소수일 경우
- G-mean: 제1종 오류와 제2종 오류 중 성능이 나쁜쪽에 더 가중치를 둠
- F1 measure: 지표나 불량에 관여하는 지표인 정밀도와 재현율만 고려함
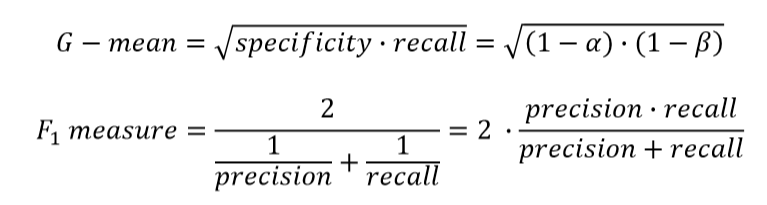
'데이터사이언스' 카테고리의 다른 글
| Ridge regression과 LASSO regression (0) | 2019.06.20 |
|---|---|
| 다중선형회귀에서 다중공선성 문제와 해결방법 (0) | 2019.06.20 |
| 분산과 편파성의 트레이드오프 (0) | 2019.06.18 |
| 모형의 적합성에 대한 교차검증을 수행하는 방법 (0) | 2019.06.18 |
| 데이터 분할 - 학습데이터, 검증데이터, 테스트데이터의 각 열할은? (0) | 2019.06.18 |



