분산(Variance)과 편파성(Bias)는 Tradoff 관계
- 분산: 전체 데이터의 집합 중 다른 학습 데이터를 이용했을때, f_hat이 변하는 정도 (복잡한 모형일수록 분산이 높음)
- 편파성: 학습 알고리즘에서 잘못된 가정을 했을때 발생하는 오차 (간단한 모형일수록 편파성이 높음)
- 복잡한 모형 f_hat(X)을 사용하여 편파성을 줄이면, 반대로 분산이 커짐 (간단한 모형일 경우엔 반대의 현상이 발생)
- 따라서 분산과 편파성이 작은 모형을 찾아야함
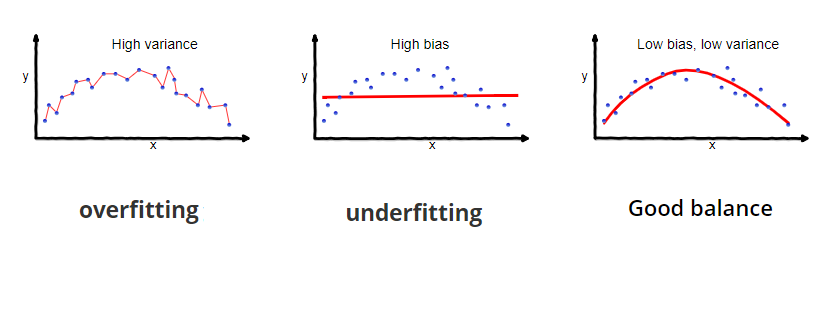
모형의 적합성을 평가하는 방법
- Overfitting: 가장 높은 복잡도를 가지므로 학습 집합에 과적합 되어 분산이 높아짐. 따라서 검증데이터의 성능 지표가 Good balance에 비해 안좋음
- Underfitting: 가장 낮은 복잡도를 가지므로 편파성이 높아져 가장 안좋은 성능 지표를 갖음
- Good balance: 실제 모형과 가장 유사한 형태로 분산과 편파성이 모두 적절히 낮아져 검증 데이터의 성능 지표가 가장 좋음
'데이터사이언스' 카테고리의 다른 글
| 다중선형회귀에서 다중공선성 문제와 해결방법 (0) | 2019.06.20 |
|---|---|
| 분류 모형 성능 지표 (제1종 오류, 제2종 오류, 정확도, 정밀도, 재현율, 특이도) (1) | 2019.06.19 |
| 모형의 적합성에 대한 교차검증을 수행하는 방법 (0) | 2019.06.18 |
| 데이터 분할 - 학습데이터, 검증데이터, 테스트데이터의 각 열할은? (0) | 2019.06.18 |
| 좋은 머신러닝 모형을 만들기 위한 7가지 단계 (0) | 2019.06.18 |



